Page 1 of 1
Is pDev threshold of 0.05 the only choice when using PAL_PFML_GoodnessOfFit.m
Posted: Wed Nov 27, 2024 6:44 am
by Lala
I have just collected data in a perceptual task on facial expressions, judging said expressions, is it a or b, in each trial, using a psi method to optimise the use of the trials for the data, but a large number have produced quite spread out data sets, as responses have sometimes been a little inconsistent, producing a bit of spread away from the parametric function line of best fit. I get a parametric functions for each condition to look at , as well as the key measure we are using - Point of subjective equality- ie the % of emotion a reqired where there is equal probability of them answering yhey see emotion a or b in the face. I am assessing which cases to exclude or inlude in my analysis and have access to outputs from a PAL_PFML_GoodnessofFit script that has been run on the data I gathered. I have read up on pdev, that the p value needs to be obver 0.05 for the fit to be considered acceptable, but there are noted issues around this as an arbitrary level chosen simply because it has become convention. The data is quite noisy because the participants have found the task quite difficult (a 1 AFC judging if a face shows one or another of two emotions). So I am looking for approaches to decide which to keep that might be a little more robust- in the same way that some researchers use p<0.01 instead of 0.05 when they want to have higher confidence in their statistical approach.
(The data gathering script uses psi adaptive method via PAL_AMPM with cumulative normal type parametric function)
Other suggestions around approaches to excluding data or dealing with very messy data always appreciated
Thanks!
Re: Is pDev threshold of 0.05 the only choice when using PAL_PFML_GoodnessOfFit.m
Posted: Wed Nov 27, 2024 12:55 pm
by Nick Prins
Ask twelve people for their opinion on this and you’re likely to get 13 different answers. Maybe others will join in to this discussion but here’s my two cents. Your model makes assumptions, e.g., ‘the true relation between stimulus intensity and the probability that the participant will make response ‘A’ follows a cumulative normal distribution’ or ‘the upper asymptote equals 0.97 (i.e., the lapse rate equals 0.03)’. Obtaining a poor goodness-of-fit simply means you have reason to believe that at least one of your assumptions is wrong. But that shouldn’t really concern you much per se. All models of human behavior are wrong. So, which side of alpha = 0.05 your goodness-of-fit p ends up at depends not on whether your model is wrong or not (your model is wrong, they’re all wrong), rather it depends on how wrong it is but also on how many data you have. Your model can be just a little wrong, but with a lot of data you will still get a poor goodness-of-fit. Your model can be very, very wrong but if you have just a few data your goodness-of-fit can still be good.
Now, if you can think of a theoretically meaningful, hopefully simple, modification to your model that will much improve your goodness-of-fit then that is awesome and useful. E.g., maybe it helps your model if you allow PSEs or slopes to differ depending on whether the face in the stimulus is male or female or whatever. If something like that improves your model then you learned something about the mechanism you’re interested in. And that’s the whole point of research. But I personally don’t see much point in tweaking data or trying alternative ways to determine goodness-of-fit until you find something that says your fit is good. For one, to do that ethically you would have to report the whole story (e.g., “I first did a standard goodness-of-fit but my p was less than 0.05, so then I kept trying stuff until I found a procedure that gave me p > 0.05”). Instead, stand proud, report it, and own it. Your model is wrong, so what? They’re all wrong.
That said, here are some things though you could try that would be meaningful modifications to your model. I don’t know what your IV is (it seems to be something like ‘amount of emotion’ but I’m not sure how you quantified it) but one meaningful way in which your model might be wrong is that the shape of the PF is assumed to be normal if IV is expressed on a linear scale (as opposed to say a logarithmic scale). Or perhaps you assume that the lapse rate is 0 but participants do in fact lapse. It sounds like your task is ‘appearance-based’ and the probability of response ‘A’ runs from 0 to 1 (if it weren’t for lapses). What we see quite a bit is that researchers in that situation will allow for lapses at the upper asymptote (by freeing the 'lambda' parameter or setting it to, say, 0.03) but fix the lower asymptote at 0. That makes no sense. Instead, one should set the lower asymptote to the lapse rate also (see PAL_PFML_gammaEQlambda_Demo.m in the PalamedesDemos folder for example of this).
Re: Is pDev threshold of 0.05 the only choice when using PAL_PFML_GoodnessOfFit.m
Posted: Thu Nov 28, 2024 4:51 am
by Lala
Hi, thanks for the speedy reply. A bit more information- the lapse rate and priorgamma are both set to 0.03- re the gammaEQlambda set up you refer to. Faces are amorph between emotion a and b with 21 levels, 5% change between each, they do 6 blocks of 96 trials, so a fairly good number of trials per condition, I hope. I think I gave you slightly the wrong idea with my earlier post- at the moment I am not looking to change the model to achieve a better p value- not a great approach as you describe, but instead I am trying to check that my current way of deciding which data cases to include or exclude is the best choice. You are right, it is appearance based- the key IV is the PSE, the point at which they are equally as likely to say the face shows emotion a or b, it is in % and so a meaningful result should be between 0 and 1, since outside of that range does not make a lot of sense. So I have excluded all that fall above 1 or under -1, but some of the remaining cases have quite a lot of spread away from the psychometric function produced- so I guess I am looking for other approaches to either validate the current approach, or possibly find a different threshold to exclude more cases. I have not looked at the pdev for each case yet, so it might be that retaining those over 0.05 might result in the same data set to analyse- or it might have a different result. But from your info in your book with Kingdom, Psychophysics, an Introduction,2016 (this is great, I will read a lot more of it when i get the time), the description of 0.05 as only a way to exclude "unacceptably poor" sounded like it might be overly-lenient. I thought some might have a stricter allowance for pdev, in the same way some researchers use p<0.01 to be more strict. The main issue with the experimental set up seems to be that some people find the task very hard- the image is seen for half a second, and a common feedback from the participants is that they feel quite conflicted about which emotion they see more dominantly- so on some presentations of face morph they choose emotion a, but another time they choose emotion b and if this happens enough it resembles random responding and we cannot use their data. For this study that is what it is, I had to lose about 1/3 of my data (a bit heartbreaking), but for the next iteration I am havinga think how to improve things to not lose so much data. Particularly since I have the feeling , having watched all the participation, that everyone was trying pretty hard to do the task, it's not an engagement issue (I think). So this suggests that their data is still meaningful, they are not as good as discerning the change in emotional content in the face, these are kind of the people we are as interested in as those who do it easily. The faces are shown on bodies, not alone, we are looking at it in that context. Thanks so much for your advice on this.
Re: Is pDev threshold of 0.05 the only choice when using PAL_PFML_GoodnessOfFit.m
Posted: Thu Nov 28, 2024 9:04 pm
by Nick Prins
Yes, I did misunderstand. I thought you were trying to keep the data but make the fits acceptable, one way or another. There really is no ‘clean’ way to exclude bad data from an analysis. There is no rule that says that if your goodness-of-fit p is less than 0.05 (or any other number) you can simply ignore the data. My view on this type of situation is that you can come up with any rule that you want to separate your data into a good pile and a bad pile. But you then have to report what that rule is and why you are using it, and see whether you can convince people that your rule was reasonable and that your conclusions are still valid even though they are based on only a select subset of your participants. I don’t think our text would call any specific pDev cut-off value better than another. Not intentionally anyway.
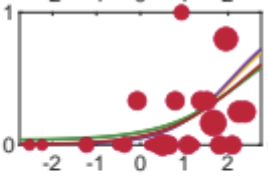
I’m not sure what your data look like exactly but one way to handle the occasional poor dataset is to use a hierarchical analysis. It would analyse all your participants in one go. Simply put, the idea is that the model shares information between participants (simply put, it is a bit as if the model says something like: ‘well, the slopes for the other participants all had a value around 1, so the slope for this participant probably has a value around 1 also’).
The image below, for example, shows real human data that would probably not result in a successful fit if analyzed individually. The PSE is just barely within the range of stimulus intensities used (it sounds like you have a few datasets like that as well). But it fit just fine in a hierarchical analysis (multiple fits are shown of models that differ in their assumptions). The PAL_PFHB routines can do a Bayesian hierarchical analysis. The figure is from this paper, which specifically discusses the hierarchical approach:
https://osf.io/qha6r It is a pre-peer review, much more elaborate version of this paper:
https://rdcu.be/c4fsG
Re: Is pDev threshold of 0.05 the only choice when using PAL_PFML_GoodnessOfFit.m
Posted: Mon Dec 02, 2024 5:19 am
by Lala
Thank you so much for the reply, I will read up on the hierarchical analysis, thanks.